Referring Expression Comprehension (REC) is a task of grounding the referent based on an expression, and its
development is greatly limited by expensive instance-level annotations. Most existing weakly supervised
methods are built based on two-stage detection networks, which are computationally expensive. In this paper,
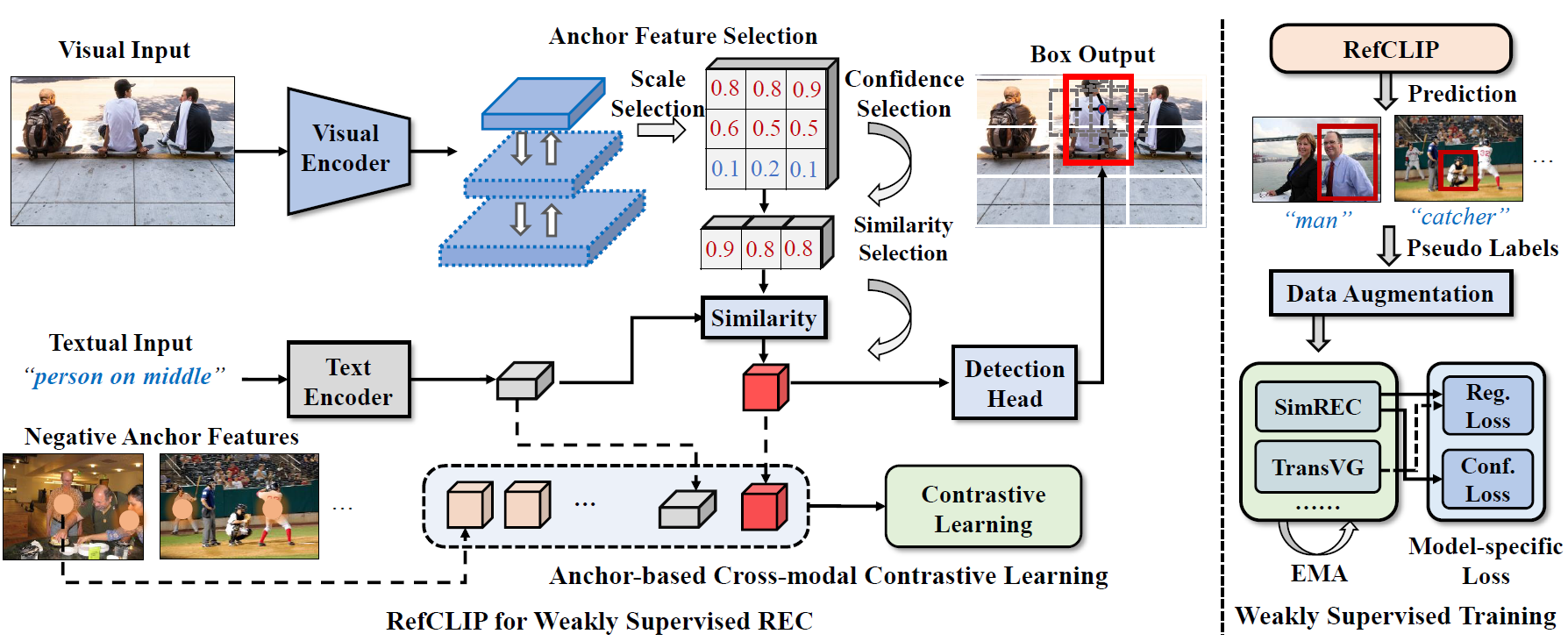
we resort to the efficient one-stage detector and propose a novel weakly supervised model called RefCLIP.
Specifically, RefCLIP redefines weakly supervised REC as an anchor-text matching problem, which can avoid
the complex post-processing in existing methods. To achieve weakly supervised learning, we introduce
anchor-based contrastive loss to optimize RefCLIP via numerous anchor-text pairs. Based on RefCLIP, we
further propose the first model-agnostic weakly supervised training scheme for existing REC models, where
RefCLIP acts as a mature teacher to generate pseudo-labels for teaching common REC models. With our careful
designs, this scheme can even help existing REC models achieve better weakly supervised performance than
RefCLIP, e.g., TransVG and SimREC. To validate our approaches,
we conduct extensive experiments on four REC benchmarks, i.e., RefCOCO, RefCOCO+, RefCOCOg and ReferItGame.
Experimental results not only report our significant performance gains over existing weakly supervised
models, e.g., +24.87% on RefCOCO, but also show the 5x faster inference speed.